Overview
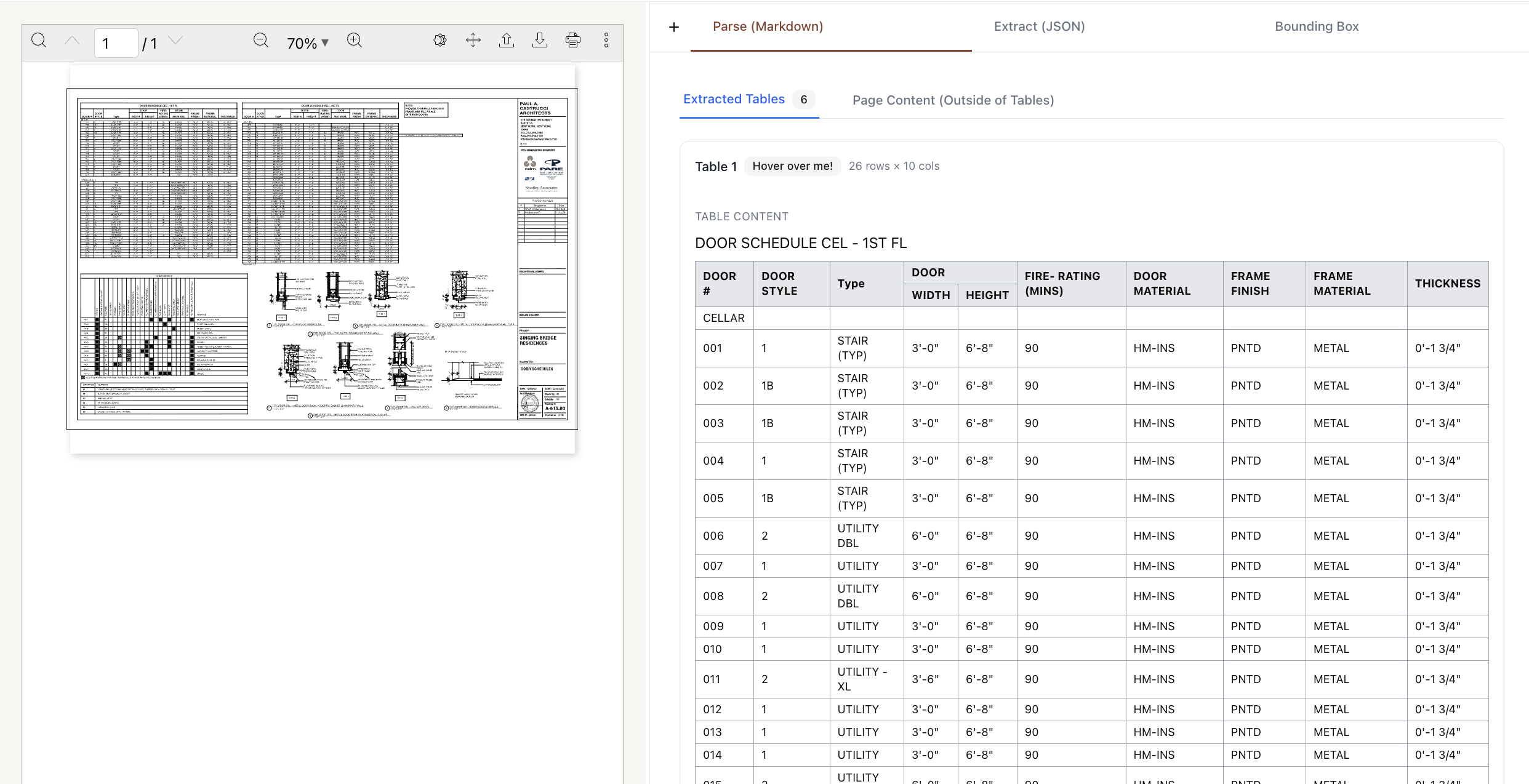
Cardinal detects and processes dense PDFs — cases where a document contains many small-text elements that are difficult to parse cleanly with normal extraction. When dense PDF detection is enabled, Cardinal splits the PDF into all of its individual table elements and extracts all the remaining text outside of those tables. Results are returned as structured elements under theprocessed_tables field along with the extracted content from non-table areas.
For each table element, you’ll receive:
table_index– index of the table on the page.page_number– page where the table appears.bounding_box– normalized geometry includingmin_x,min_y,max_x,max_y, plus row/column counts and polygon coordinates.row_count/column_count– detected table dimensions.image_format– output crop format (e.g.png).crop_coordinates– pixel coordinates for cropped table images.dpi_x/dpi_y– resolution used for rendering.text_content– extracted HTML/Markdown table text.html_code– cleaned HTML version of the table (when available).
How to Enable
To enable dense PDF detection, setdensePdfDetect: true in your API request.
- Default:
densePdfDetect = false - To enable dense PDF detection, set
densePdfDetect = true. - ⚠️ Enabling dense PDF detection will add latency to your requests, since additional detection passes are run.
Example Response (excerpt)
Why Dense PDF Detection?
Some engineering, financial, and architectural documents contain dozens of tiny tables (e.g., schedules, parts lists, cell plans) that break normal Markdown extraction. Dense PDF detection solves this by:- Isolating each table element: Splits the PDF into individual table components with precise bounding boxes
- Extracting non-table content: Captures all remaining text outside of the identified table areas
- Providing structured output: Delivers both cropped table images for visual reference and extracted HTML/Markdown text for structured parsing
Dense PDF extraction requires the
densePdfDetect parameter to be enabled in your API request. Results appear in the JSON output under processed_tables along with extracted content from non-table areas.